【目次】Teamsプレゼンス可視化ツール
| 0. プロローグ | 1. 永続的なアクセストークンの取得 | 2. プレゼンスの取得 | 3. エクセルで可視化 |
| 4. PowerAutomate Desktopで定期実行 | 5. Pythonで実装 | 6. 完全自動化Pythonプログラム |
このシリーズかなり人気コンテンツです。「Teams 監視」「Teams 監視 会社」みたいな検索ワードで来られる方が多いこと多いこと。皆さん、そんなにサボってますか。まあサボっちゃいますよね。テレワークのメリットは色々ありますが、最大のメリットはベットが近くにあることですかね。そして最大のデメリットはベットが近くにあることですかねえ。
Microsoft Teamsプレゼンス自動取得Pythonプログラム
前回の記事で書いたPythonプログラムは人の出入りがあるたびにコードを書き換えないといけませんでした。私の会社はブラック企業なので人の出入りが多い!そのたびにコードを書き換えるのは面倒くさい!ということで、メンバーの増減が発生してもコードを書き換える必要がない完全自動化Pythonプログラムにアップデートしました。
プログラム動作フロー
動作フローは以下の通り。
- 特定のTeamsチャンネルからメンバーリストを取得
- 取得したメンバーリスト全員のTeamsプレゼンスを一括で取得
- TeamsプレゼンスをCSVファイルに書き込み
CSV形式で出力するので、あとはBIツールで分析するもよし、Excelに取り込むもよし好きなように加工できます。
プログラム① CSVファイルのヘッダー行とIDリストの作成
#!/usr/bin/python
# coding: UTF-8
#実行時間を取得
import datetime
dt_now = datetime.datetime.now()
datenow = "{0:%Y/%m/%d}".format(dt_now)
timenow = "{0:%H:%M:%S}".format(dt_now)
weeknow = "{0:%a}".format(dt_now)
import requests
import json
import os
#各種ファイルを変数に代入
tokenfile = "./token.txt"
idsfile = "./ids.json"
csvfile = "./presence.csv"
resultfile1 = "./result1.json"
#アクセストークンの読み取り
token = open(tokenfile, "r" , encoding="utf-8-sig")
access_token = token.read().strip()
token.close
headers = {'Authorization': 'Bearer {}'.format(access_token)}
# メンバーリスト取得
url1 = "https://graph.microsoft.com/v1.0/groups/[groups id]/members"
result1 = requests.get(url1, headers=headers,)
jsondata1 = (result1.json())
user_surname = [user["surname"] for user in jsondata1["value"]]
##メンバーリストのCSVファイル作成
#時刻書き込み
csv = open(csvfile, "w")
csvdata = [
f"{datenow}",",",
f"{timenow}",",",
f"{weeknow}",",",
]
csv.writelines(csvdata)
#user_principal_names書き込み
for row in [user_surname]:
csv.write(",".join(map(str, row)) + "\n")
csv.close()
##idリストのJSONファイル作成
#id取得
ids = [user["id"] for user in jsondata1["value"]]
str_ids = json.dumps(ids)
idsjson = open(idsfile, "w")
idslist = [
"{ \"ids\": ",
]
idsjson.writelines(idslist)
#idリスト書き込み
for row in [str_ids]:
idsjson.write(",".join(map(str, [row])))
idslist = [
" }",
]
idsjson.writelines(idslist)
idsjson.close()
#出力結果をファイルに保存
result = open(resultfile1, "w")
json.dump(jsondata1, result)
result.close
解説
#アクセストークンの読み取り https://note.nkmk.me/python-requests-web-api/
token = open(tokenfile, "r" , encoding="utf-8-sig")
access_token = token.read().strip()
token.close
headers = {'Authorization': 'Bearer {}'.format(access_token)}
アクセストークンはこの手順で取得したものをファイルに保存し、読み取ります。”utf-8-sig”はDOM付きUTF-8の場合指定が必要です。読み取ったトークンをベアラー認証として使用します。
# メンバーリスト取得 url1 = "https://graph.microsoft.com/v1.0/groups/[groups id]/members" result1 = requests.get(url1, headers=headers,) jsondata1 = (result1.json()) user_surname = [user["surname"] for user in jsondata1["value"]]
続いてメンバーリストを取得します。取得するMicrosoft Graph APIエンドポイントは以下です。
https://graph.microsoft.com/v1.0/groups/[groups id]/members
[groups id]にはプレゼンスを取得したいメンバーが所属しているTeamsグループのIDを指定します。
変数名 surname に姓が入っているのでfor文で人数分取り出します。
##メンバーリストのCSVファイル作成
#時刻書き込み
csv = open(csvfile, "w")
csvdata = [
f"{datenow}",",",
f"{timenow}",",",
f"{weeknow}",",",
]
csv.writelines(csvdata)
#user_principal_names書き込み
for row in [user_surname]:
csv.write(",".join(map(str, row)) + "\n")
csv.close()
CSVファイルのヘッダー行を作成します。日時と取り出したsurnameをカンマ区切りで書き込みます。
##idリストのJSONファイル作成
#id取得
ids = [user["id"] for user in jsondata1["value"]]
str_ids = json.dumps(ids)
idsjson = open(idsfile, "w")
idslist = [
"{ \"ids\": ",
]
idsjson.writelines(idslist)
#idリスト書き込み
for row in [str_ids]:
idsjson.write(",".join(map(str, [row])))
idslist = [
" }",
]
idsjson.writelines(idslist)
idsjson.close()
同様にメンバーリストからUUIDを取り出します。UUIDは変数名 id に入っているのでfor文で取り出しつつ、JSONの辞書型として保存します。
これで土台となるCSVファイルが出来上がります。
プログラム② プレゼンスの取得とCSVファイルへの書き込み
#!/usr/bin/python
# coding: UTF-8
#実行時間を取得
import datetime
dt_now = datetime.datetime.now()
datenow = "{0:%Y/%m/%d}".format(dt_now)
timenow = "{0:%H:%M:%S}".format(dt_now)
weeknow = "{0:%a}".format(dt_now)
import requests
import json
import os
import shutil
#各種ファイルを変数に代入
tokenfile = "./token.txt"
idsfile = "./ids.json"
csvfile = "./presence.csv"
resultfile2 = "./result2.json"
#アクセストークンの読み取り
token = open(tokenfile, "r" , encoding="utf-8-sig")
access_token = token.read().strip()
token.close
headers = {'Authorization': 'Bearer {}'.format(access_token)}
##############
# プレゼンス取得 #
##############
#idリストの読み取り
ids = open(idsfile, "r")
idslist = json.load(ids)
ids.close
#URLをセット
url1 = "https://graph.microsoft.com/v1.0/communications/getPresencesByUserId"
#requests.postを使ってアクセスし、jsondataに格納
result1 = requests.post(url1, headers=headers, json=idslist)
jsondata1 = (result1.json())
presences = [user["availability"] for user in jsondata1["value"]]
#CSVファイル書き込み
csv = open(csvfile, "a")
csvdata = [
f"{datenow}",",",
f"{timenow}",",",
f"{weeknow}",","
]
csv.writelines(csvdata)
for row in [presences]:
csv.write(",".join(map(str, row)))
csvdata = [
"\n"
]
csv.writelines(csvdata)
csv.close()
#出力結果をファイルに保存
result = open(resultfile2, "w")
json.dump(jsondata1, result)
result.close
2つ目のプログラムは定期的に実行してプレゼンスを追記していくプログラムです。
#idリストの読み取り ids = open(idsfile, "r") idslist = json.load(ids) ids.close
プログラム①で作成したUUIDリストを読み込みます。
#URLをセット url1 = "https://graph.microsoft.com/v1.0/communications/getPresencesByUserId" #requests.postを使ってアクセスし、jsondataに格納 result1 = requests.post(url1, headers=headers, json=idslist) jsondata1 = (result1.json()) presences = [user["availability"] for user in jsondata1["value"]]
プレゼンスを取得するMicrosoft Graph APIエンドポイントは以下です。
https://graph.microsoft.com/v1.0/communications/getPresencesByUserId
このURLにJSONの辞書型にしたUUIDリストをPOSTメソッドで入力することでメンバー全員のプレゼンスを一括取得します。
プレゼンスは変数名 availability に入っているのでfor文で人数分取り出します。
#CSVファイル書き込み
csv = open(csvfile, "a")
csvdata = [
f"{datenow}",",",
f"{timenow}",",",
f"{weeknow}",","
]
csv.writelines(csvdata)
for row in [presences]:
csv.write(",".join(map(str, row)))
csvdata = [
"\n"
]
csv.writelines(csvdata)
csv.close()
最後に日時と取り出したプレゼンス一覧をカンマ区切りで書き込めばメンバーのプレゼンス一覧CSVファイルの出来上がりです。

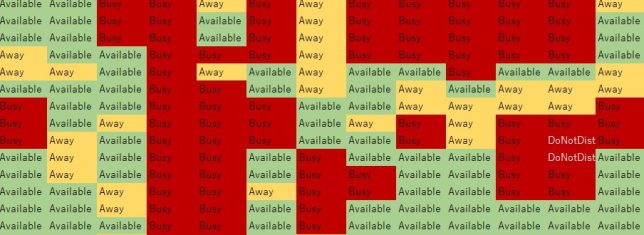
CSVファイルなのでエクセルに取り込めばこのように表示できます。エクセルの条件書式はこの記事を参考にしてください。終わり。